|
Research Scientist / Engineer
Alibaba Tongyi Lab – Wan I obtained my Ph.D. degree in Computer Science and Engineering from CUHK, supervised by Prof. Tien-Tsin WONG and Prof. Chi-Wing FU. Previously, I received my B.Sc. (1st class honor & ELITE Stream) and M.Sc. degrees in Computer Science at CUHK in 2020 and 2021 respectively. I'm focusing on video and Multi-modal Content Understanding & Generation.
Email / Google Scholar / Github / ResearchGate / LinkedIn / X / CV |

|
|
|

|
Contributors of large-scale data construction and foundation model architecture & training. |
|
|


|
Jinbo Xing, Long Mai, Cusuh Ham, Jiahui Huang, Aniruddha Mahapatra, Chi-Wing Fu, Tien-Tsin Wong, Feng Liu SIGGRAPH, 2025, Conference Proceedings Paper / arXiv / Project / Code A unified camera and object motion control framework for DiT-based image-to-video diffusion models. |


|
Yuandong Pu, Le Zhuo, Songhao Han, Jinbo Xing, Kaiwen Zhu, Shuo Cao, Bin Fu, Si Liu, Hongsheng Li, Yu Qiao, Wenlong Zhang, Xi Chen, Yihao Liu International Conference on Learning Representations (ICLR), 2026 Paper / arXiv / Project / Code A diagnostic benchmark designed to evaluate physical realism in image editing beyond semantic fidelity. |


|
Yue Ma, Kunyu Feng, Xinhua Zhang, Hongyu Liu, David Junhao Zhang, Jinbo Xing, Yinhan Zhang, Ayden Yang, Zeyu Wang, Qifeng Chen International Conference on Learning Representations (ICLR), 2026
Paper
/ arXiv
/ Project
/ Code Given an input video, Follow-Your-Creation enables 4D video creation with various camera trajectories and edited first frame, while maintaining multi-view consistency. |


|
Lvmin Zhang, Chuan Yan, Yuwei Guo, Jinbo Xing, Maneesh Agrawala SIGGRAPH, 2025, Journal Track Paper / arXiv / Project / Code Given a canvas image uploaded by a user, the framework can generate both preceding and succeeding states of the drawing process. |

|
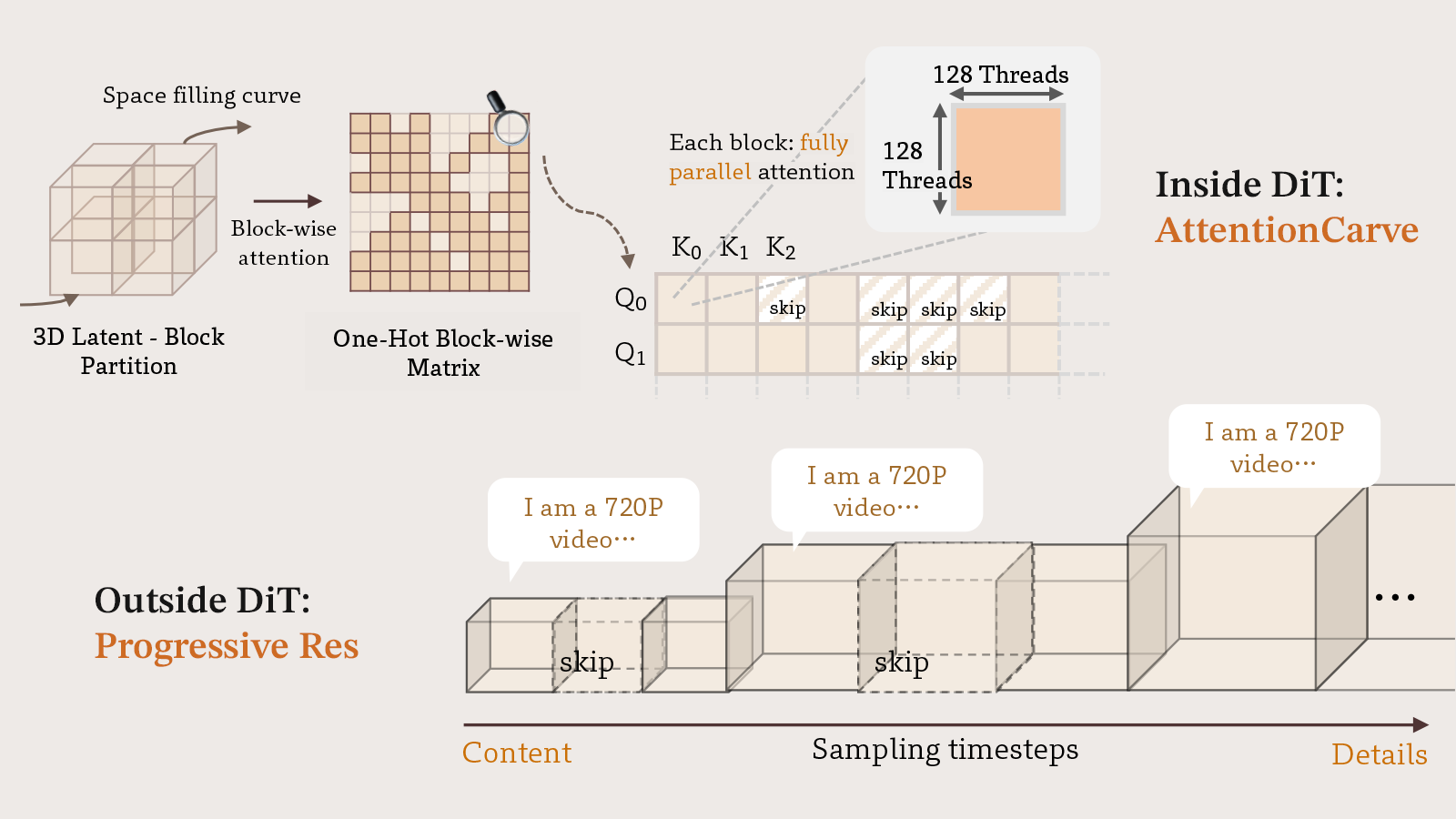
Yuechen Zhang, Jinbo Xing, Bin Xia, Shaoteng Liu, Bohao Peng, Xin Tao, Pengfei Wan, Eric Lo Jiaya Jia Neural Information Processing Systems (NeurIPS), 2025
Paper
/ arXiv
/ Project
/ Code Jenga accelerates HunyuanVideo by 4.68-10.35× through dynamic attention carving and progressive resolution generation. |


|
Mark YU, Wenbo Hu, Jinbo Xing, Ying Shan International Conference on Computer Vision (ICCV, Oral), 2025 Generating high-fidelity novel views from casually captured monocular video, while also supporting exact pose control. |


|
Yuanhao Cai, He Zhang, Xi Chen, Jinbo Xing, Kai Zhang, Yiwei Hu, Yuqian Zhou, Zhifei Zhang, Soo Ye Kim, Tianyu Wang, Yulun Zhang, Xiaokang Yang, Zhe Lin, Alan Yuille Neural Information Processing Systems (NeurIPS), 2025 A data construction pipeline and a DiT-based method for controllable subject-driven video customization. |


|
Jinbo Xing, Hanyuan Liu, Menghan Xia, Yong Zhang, Xintao Wang, Ying Shan, Tien-Tsin Wong SIGGRAPH Asia, 2024, Journal Track (selected in Technical Papers Trailer)
Paper
/ arXiv
/ Project
/ Demo
/ Code Taming large-scale video diffusion models for generative cartoon interpolation. |


|
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, Tien-Tsin Wong European Conference on Computer Vision (ECCV, Oral), 2024
Paper
/ arXiv
/ Project
/ Demo
/ Code An open-domain high-quality image-to-video foundation model. |


|
Wangbo Yu*, Jinbo Xing*, Li Yuan*, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, Yonghong Tian IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 Taming large-scale video diffusion models for high-fidelity novel view synthesis. |

|
Gongye Liu, Menghan Xia, Yong Zhang, Haoxin Chen, Jinbo Xing, Xintao Wang, Yujiu Yang, Ying Shan SIGGRAPH Asia, 2024, Journal Track
Paper
/ arXiv
/ Project
/ Demo
/ Code Given a stylized image as reference, the model can generate images and videos with consistent styles based on text prompt. |

|
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, Ying Shan arXiv preprint, 2023 An open-sourced foundational text-to-video and image-to-video diffusion model for high-quality video generation. |


|
Jinbo Xing, Menghan Xia, Yuxin Liu, Yuechen Zhang, Yong Zhang, Yingqing He, Hanyuan Liu, Haoxin Chen, Xiaodong Cun, Xintao Wang, Ying Shan, Tien-Tsin Wong IEEE Transactions on Visualization and Computer Graphics (TVCG), 2025
Paper
/ arXiv
/ Project
/ Code Given text description and video structure (depth), our approach can generate temporally coherent and high-fidelity videos. Its applications include dynamic 3d-scene-to-video creation, real-life scene to video, and video rerendering. |


|
Yue Ma, Xiaodong Cun, Sen Liang, Jinbo Xing, Yingqing He, Chenyang Qi, Siran Chen, Qifeng Chen IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025 MagicStick is a unified framework to modify video properties (e.g., shape, size, location, motion) leveraging the keyframe transformations on the extracted internal control signals. |


|
Yuechen Zhang, Jinbo Xing, Eric Lo, Jiaya Jia Neural Information Processing Systems (NeurIPS, Spotlight), 2023 Given a real-world image, our proposed method can generate its semantic-aligned variants. The approach is compatible with customized image generation, inpainting, controllable image synthesis, style transfer, etc. |

|
Yingqing He, Menghan Xia, Haoxin Chen, Xiaodong Cun, Yuan Gong, Jinbo Xing, Yong Zhang, Xintao Wang, Chao Weng, Ying Shan, Qifeng Chen AI4VA ECCV Workshop, 2024 We utilize the abundance of existing video clips and synthesize a coherent storytelling video by customizing their appearances with given visual concepts. |

|
Hanyuan Liu, Minshan Xie, Jinbo Xing, Chengze Li, Chi Sing Leung, Tien-Tsin Wong ACM Multimedia (MM), 2025 We present an effective video colorization method, an adaptation of a pre-trained text-to-image diffusion model for video colorization. |

|
Hanyuan Liu, Jinbo Xing, Minshan Xie, Chengze Li, Tien-Tsin Wong arXiv preprint, 2023 We present a novel image colorization method, which leaverages the rich diffusion model prior. It takes text-based image colorization to another semantic level. |
|
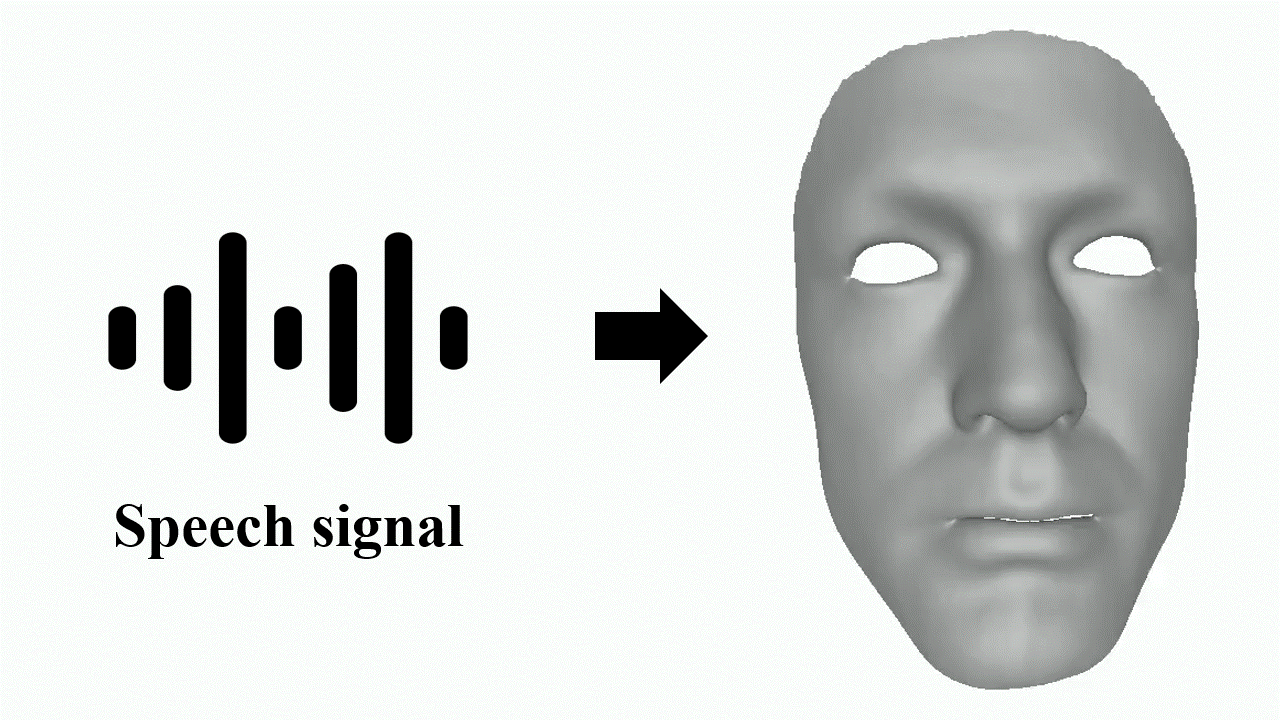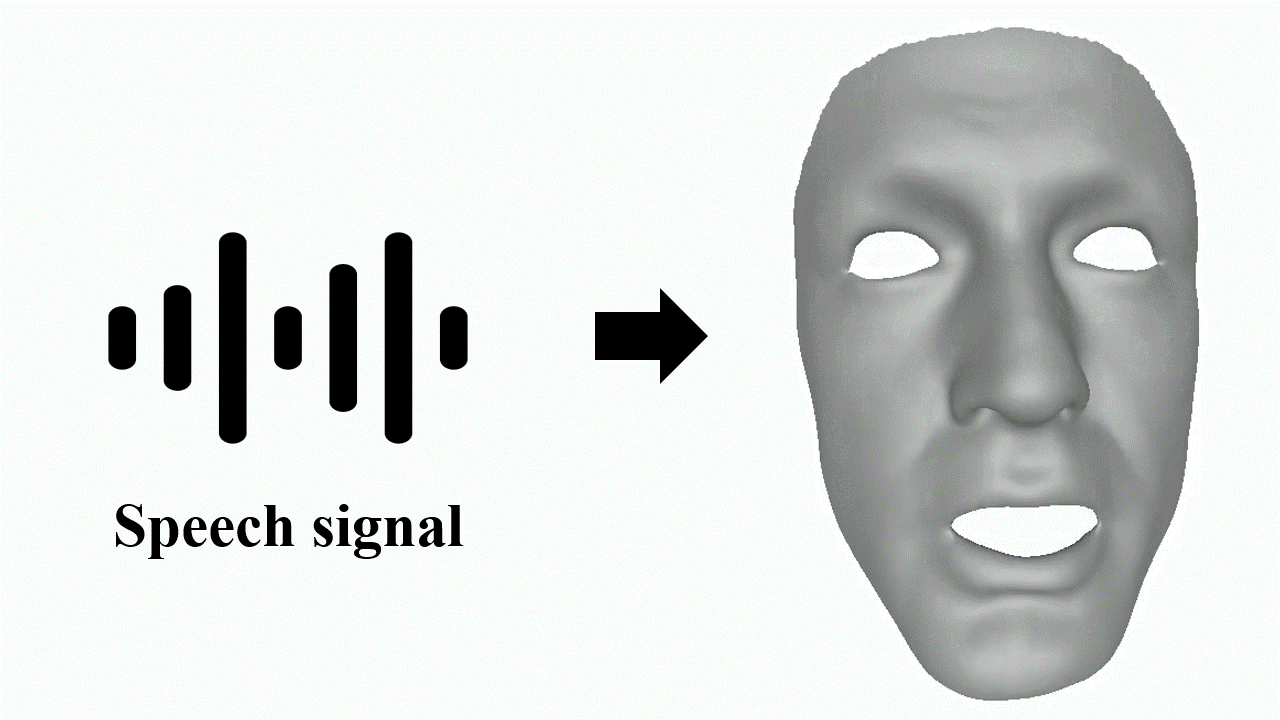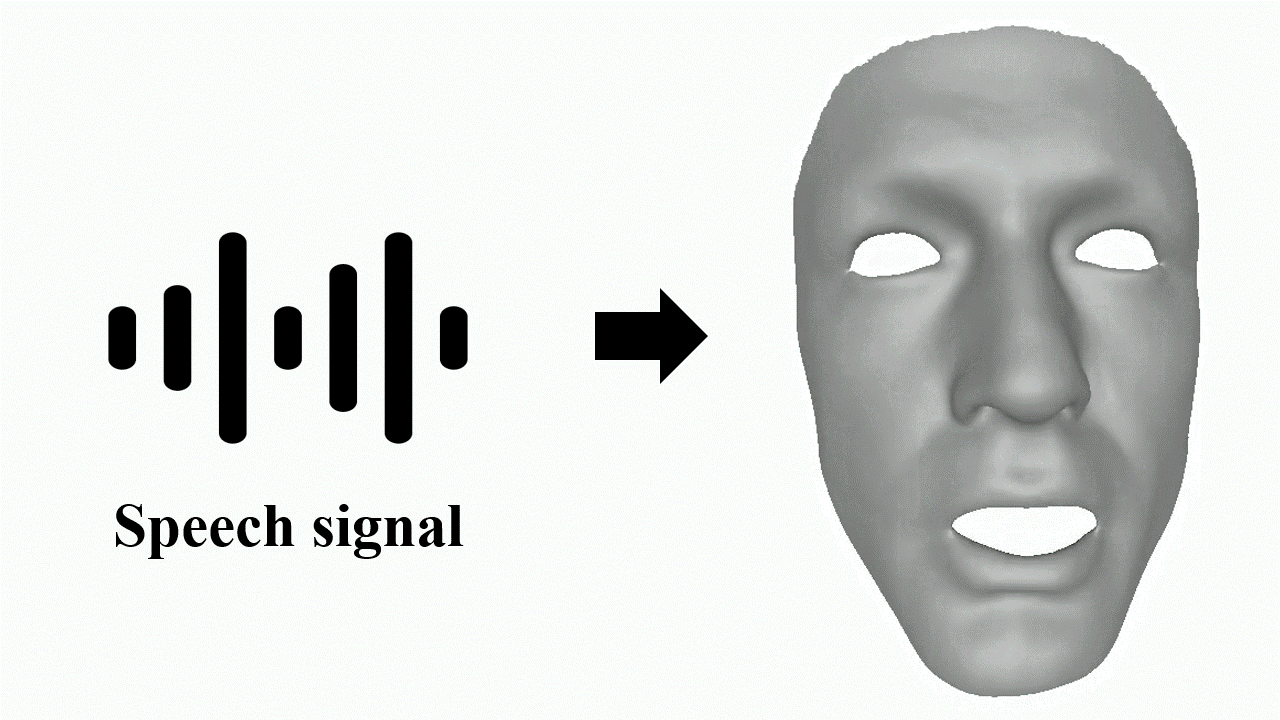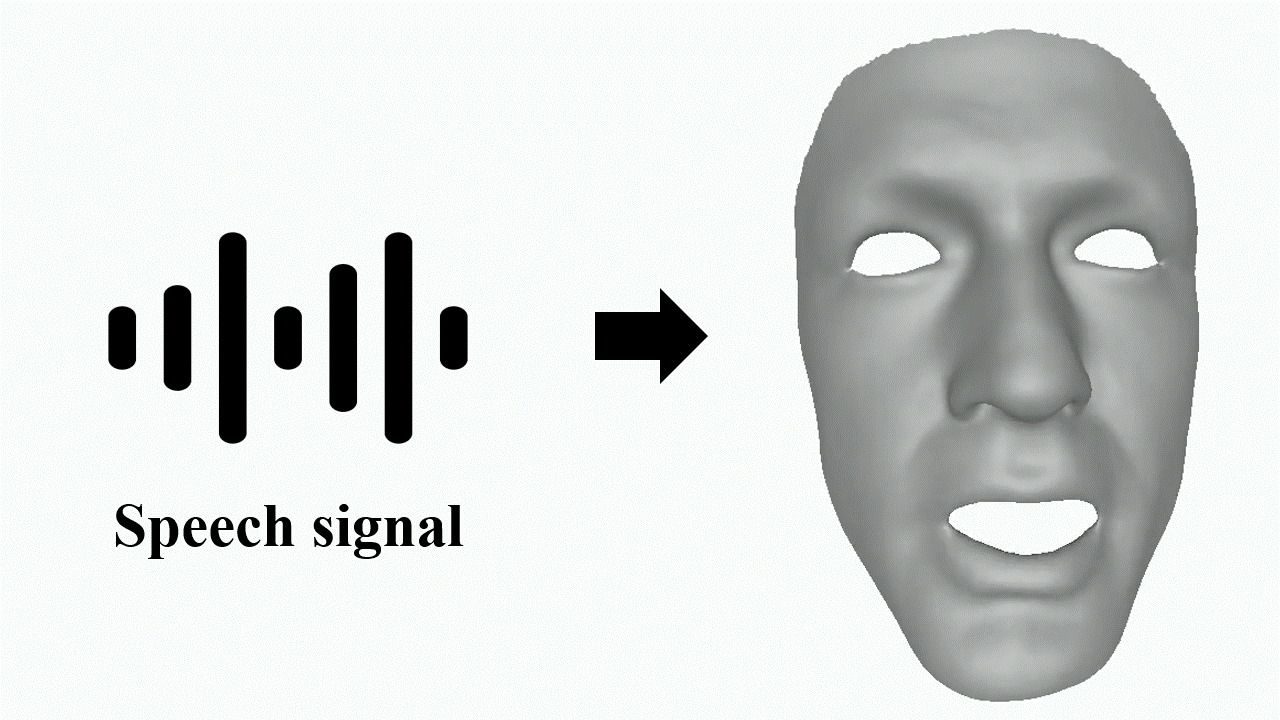
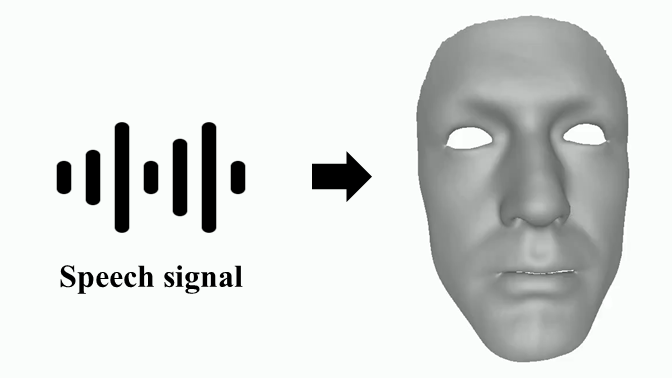
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, Tien-Tsin Wong Computer Vision and Pattern Recognition (CVPR), 2023
arXiv /
Paper /
Project /
Demo /
Code We minimize the over-smoothed facial expression using a learned discrete motion prior, which means more dramatic and expressive facial motions with more accurate lip movements can be achieved. |

|
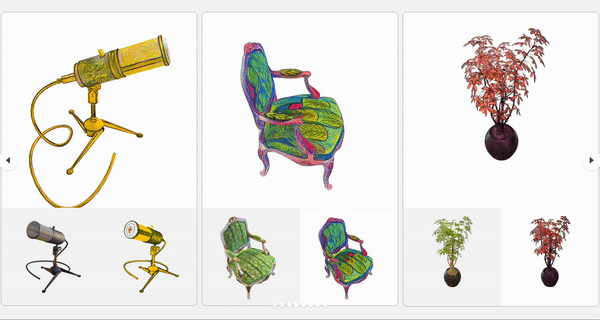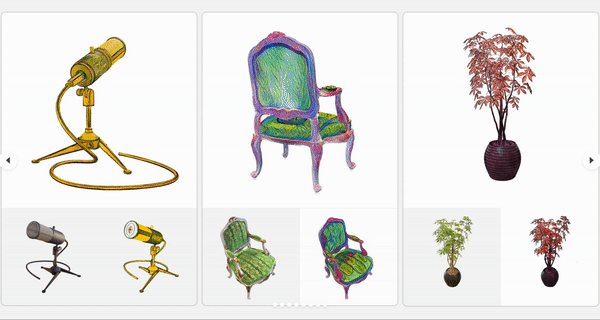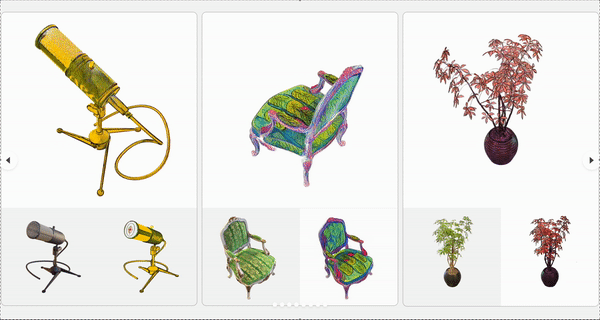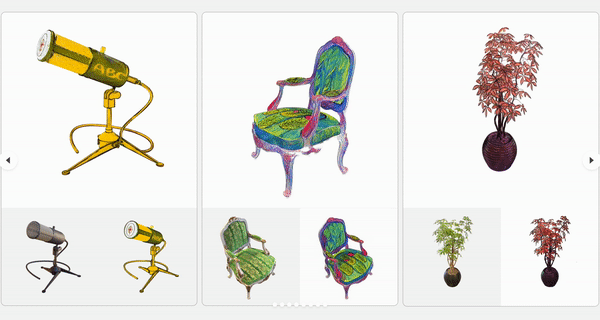
Yuechen Zhang, Zexin He, Jinbo Xing, Xufeng Yao, Jiaya Jia Computer Vision and Pattern Recognition (CVPR), 2023
arXiv /
Paper /
Project /
Video /
Data /
Code We present a controllable scene stylization method utilizing radiance fields to stylize a 3D scene, with a single stylized 2D view taken as reference. |


|
Jinbo Xing*, Wenbo Hu*, Menghan Xia, Tien-Tsin Wong IEEE Transactions on Image Processing (TIP), 2023 Paper / Project / Code / Interactive inspection We present a scale-arbitrary invertible image downscaling network (AIDN) to natively downscale HR images with arbitrary scale factors. Meanwhile, the HR images could be restored with AIDN whenever necessary. |

|
Jinbo Xing*, Wenbo Hu*, Yuechen Zhang, Tien-Tsin Wong Computational Visual Media (CVM), 2021 We present a flow-aware multi-frame interpolation method to address the complicated non-linear motions in the real world. |
|
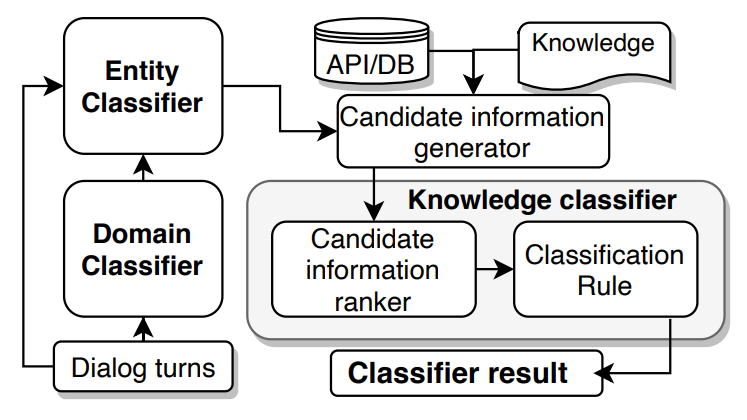
Mudit Chaudhary, Borislav Dzodzo, Sida Huang, Chun Hei Lo, Mingzhi Lyu, Lun Yiu Nie, Jinbo Xing, Tianhua Zhang, Xiaoying Zhang, Jingyan Zhou, Hong Cheng, Wai Lam, Helen Meng (All authors contribute equally) AAAI Conference on Artificial Intelligence Workshop Program (AAAIW), DSTC9, 2021 arXiv / Paper / Code / Paper Reading / Poster We propose a system capable of accessing unstructured knowledge for task-oriented dialog. |















|
|
| Alibaba Tongyi Lab (Wan) |
Research Intern Mentor: Yu Liu |
Mar. 2025 - Oct. 2025 |
| Adobe Research |
Research Scientist Intern Mentor: Dr. Long Mai |
Jul. 2024 - Jan. 2025 |
| Tencent AI Lab |
Research Intern Mentor: Dr. Menghan Xia |
Jun. 2022 - Jul. 2024 |
| Stanley Ho Big Data Decision Analytics Research Centre, CUHK |
Research Assistant Supervisor: Prof. Helen Meng |
May 2020 - Aug. 2021 |
| Electronic Engineering Dept., CUHK |
Summer Research Intern Supervisor: Prof. Ni Zhao |
May 2018 - Jul. 2018 |
|
|
-
Postgraduate Studentship
-
Distinguished Academic Performance Scholarship of MSc Programme
-
ELITE Stream Student Scholarship (2018, 2019)
-
Computer Science scholarship
-
Dean's List of Faculty of Engineering (2016, 2019, 2020)
-
Full Scholarship for Undergraduate Students (Mainland)
|
|
-
Oct.2025 "Innovation and Application of Generative Image Animation (Image-to-Video)" at GAMES Webinar.
-
Feb.2025 "Unified Motion Control for Image-to-Video Generation" at Black Forest Labs (BFL).
-
Jun.2024 "Controllable Video Generation" at Huawei.
|
|
-
Organizer: 2nd HiGen @CVPR 2026.
-
Organizer: 1st HiGen @ICCV 2025.
|
|
| 2023-2024 Spring Computational Imaging and Vision (CSCI 3290) |
| 2023-2024 Fall Advanced GPU Programming (CSCI 5390) |
| 2022-2023 Spring Introduction to Multimedia Systems (CSCI 3280) |
| 2021-2022 Spring Introduction to Multimedia Systems (CSCI 3280) |
| 2021-2022 Fall Problem Solving by Programming (ENGG 1110) |
| 2021-2022 Fall Computer Game Software Production (CMSC 5727) |
|
|
-
Journal Review:
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
IEEE Transactions on Visualization and Computer Graphics (TVCG)
International Journal of Computer Vision (IJCV)
ACM Computing Surveys (CSUR)
IEEE Transactions on Multimedia (TMM)
The Visual Computer Journal (TVCJ)
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
-
Conference Review:
ECCV 2024, MM 2024, SIGGRAPH Asia 2024
ICLR 2025, CVPR 2025, SIGGRAPH 2025, ICCV 2025, NeurIPS 2025, SIGGRAPH Asia 2025
ICLR 2026, CVPR 2026, CHI 2026, EG 2026, ECCV 2026
|
|
|
|
|
|
|
Last updated: Jan 2026
|