DynamiCrafter: Animating Open-domain
Images with Video Diffusion Priors

Showcases produced by our method (576×1024)
Showcases (320×512)
Hover over to view the input still images and text prompts.

time-lapse of a blooming flower on a stem
|

a train traveling through a field of flowers and grasses
|
|---|---|

pouring honey onto some slices of bread
|

a lighthouse with waving ocean
|
Showcases (256×256)
Hover over to view the input still images and text prompts.

bear playing guitar happily, snowing
|

boy walking on the street
|

cat dancing
|

cowboy riding a bull over a fence
|

zoom-in, a landscape, springtime
|
|---|---|---|---|---|

two people dancing
|

explode colorful smoke coming out
|

A blonde woman rides on top of a moving washing machine into the sunset.
|

girl talking and blinking
|

sailing ship in the ocean, waves are surging
|
Comparisons with baseline methods
We compare our method against existing methods using still images with a wide range of content (e.g., landscape, human, animal, vehicle, statue) and style (e.g., real-life, AI-generated, painting, clay, anime, isometric illustration).






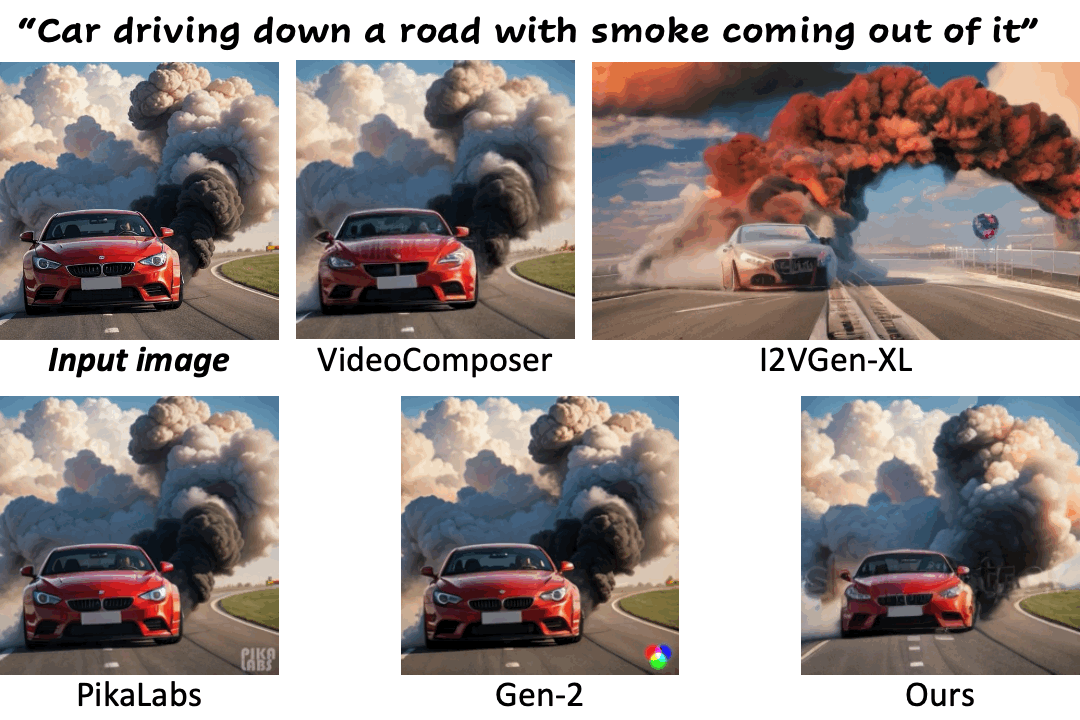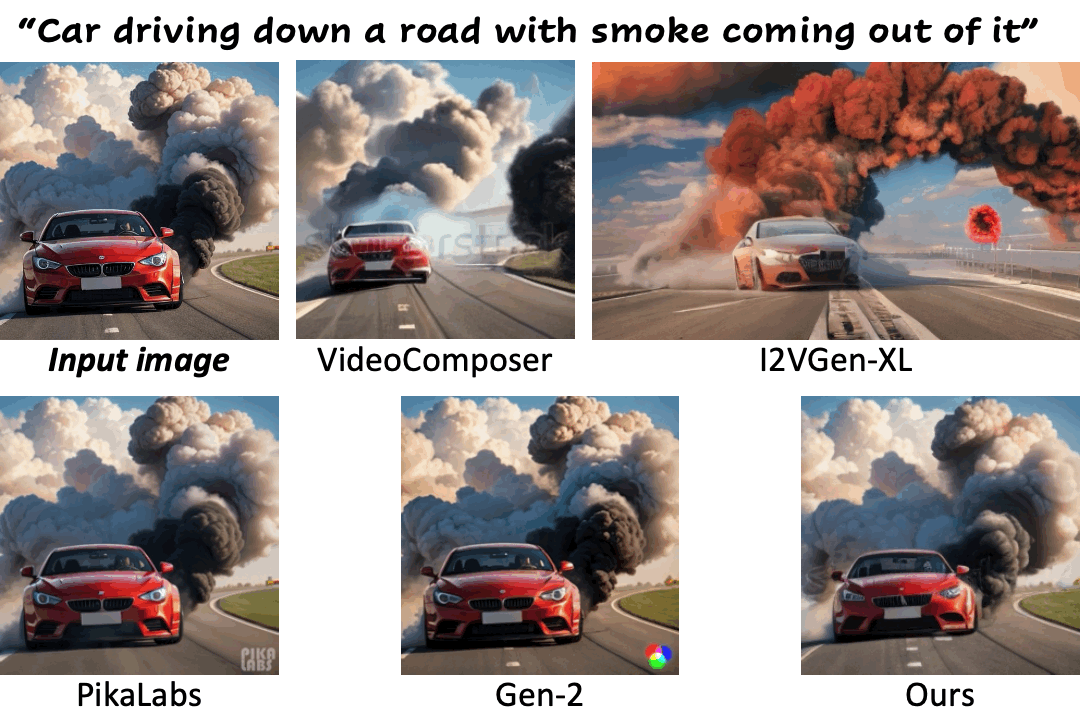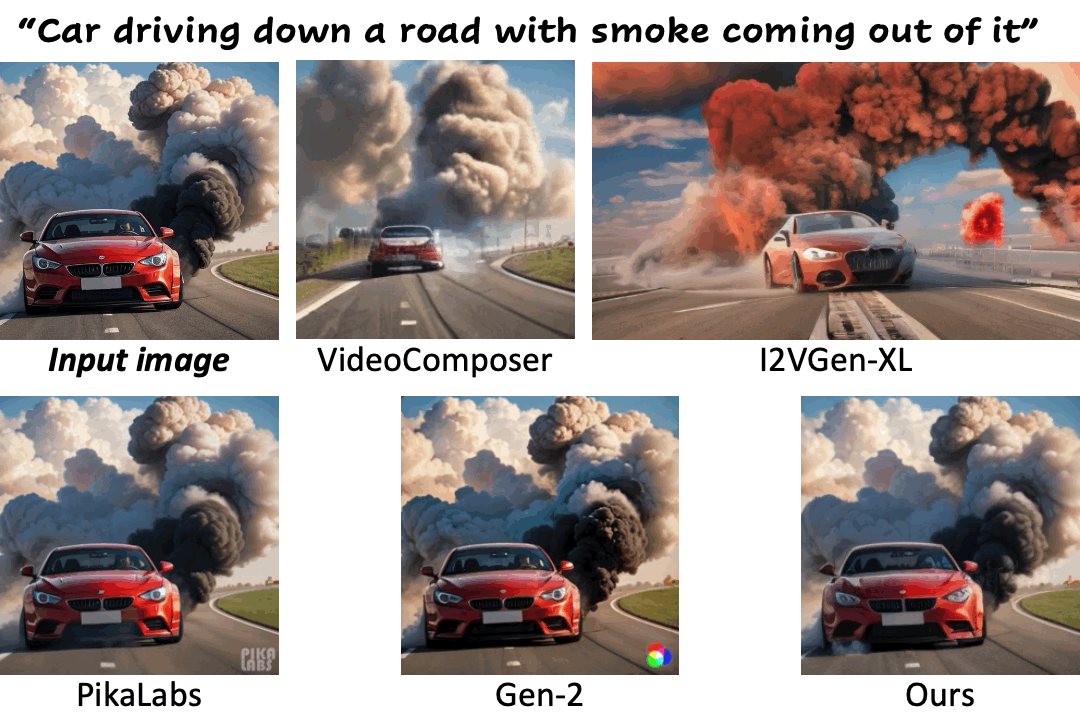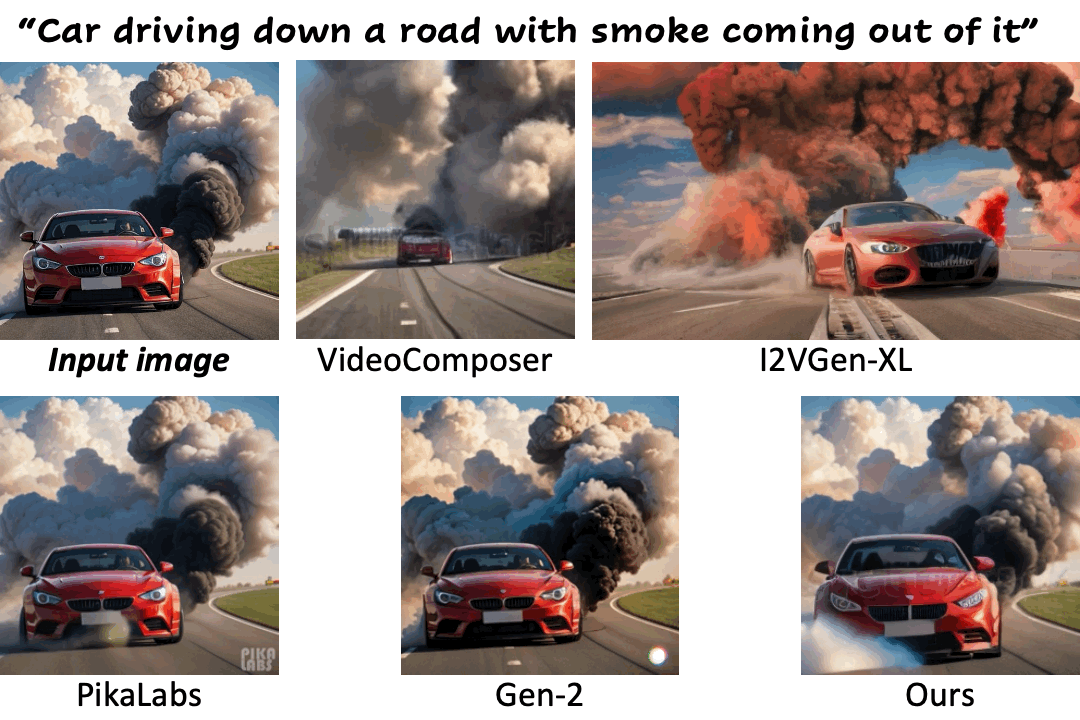








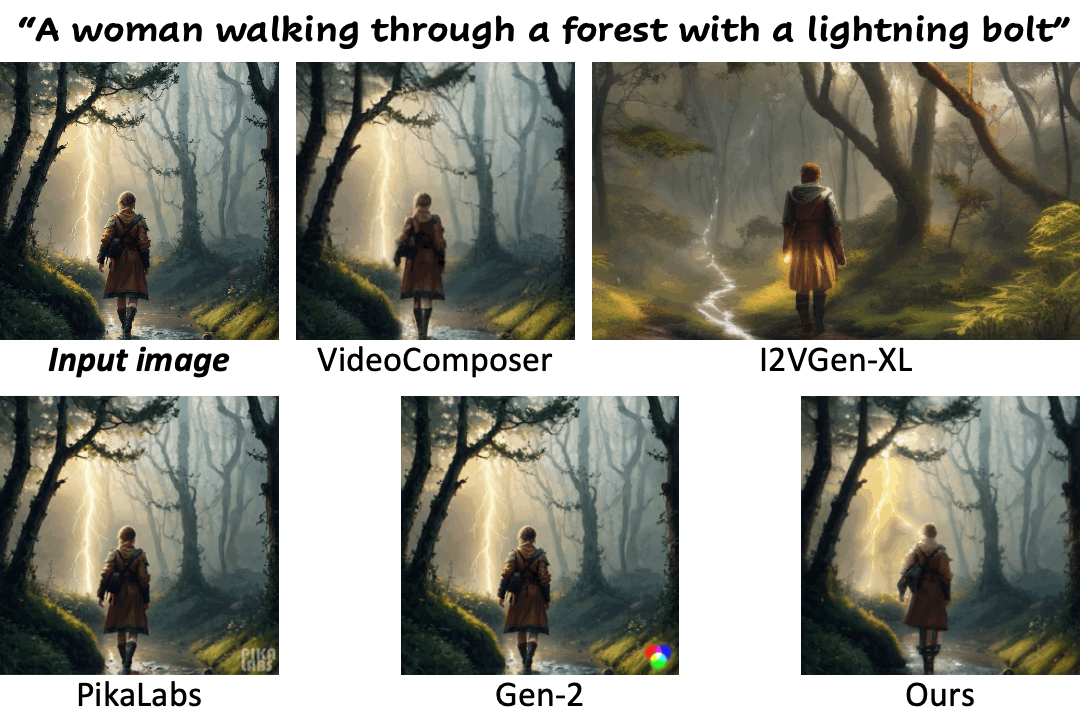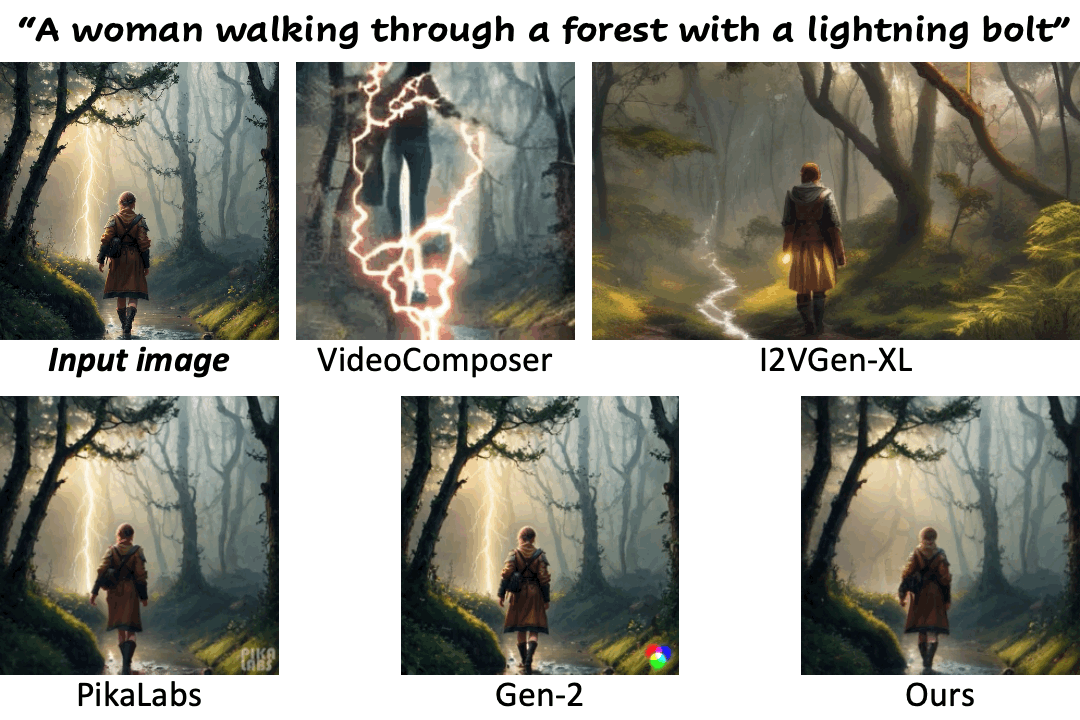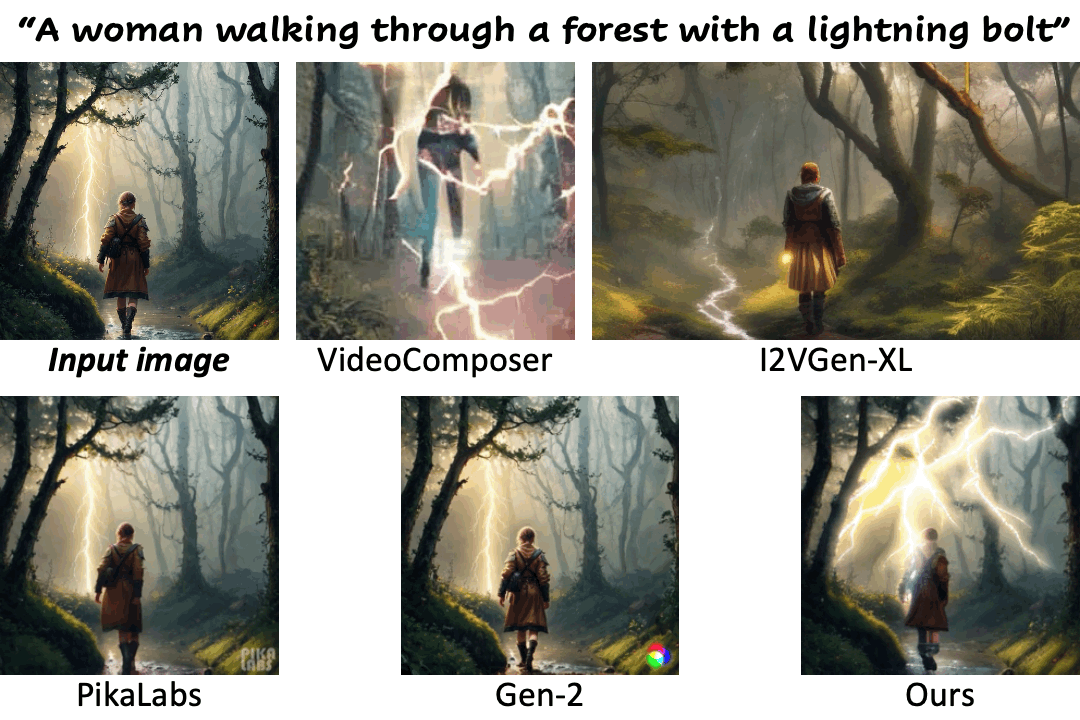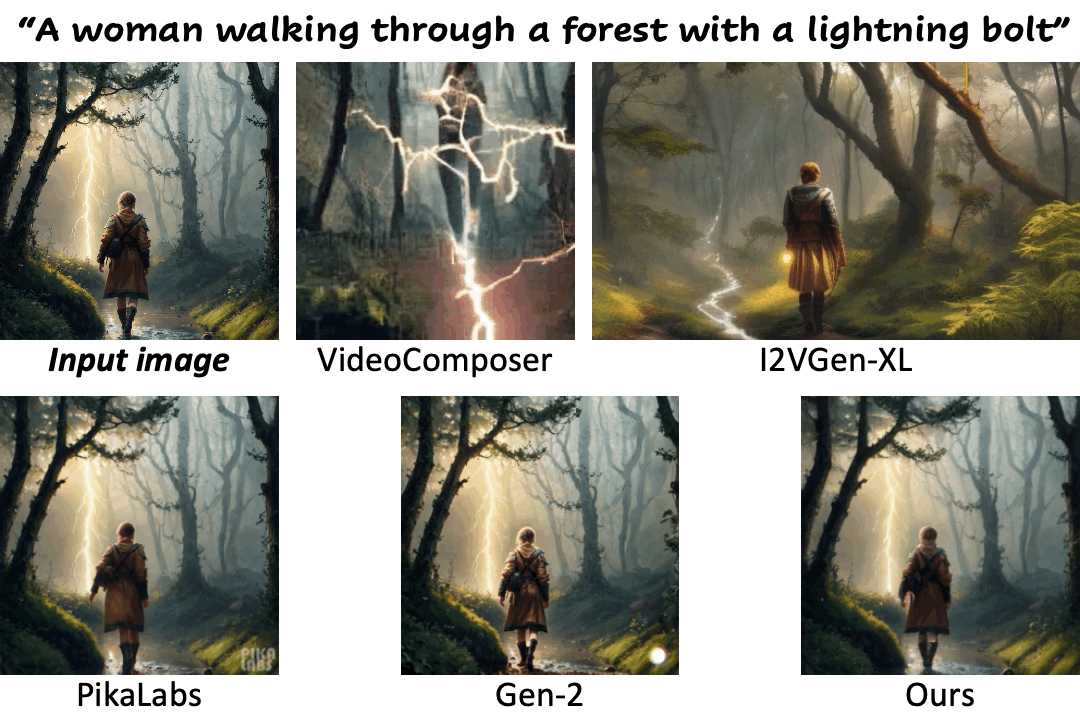
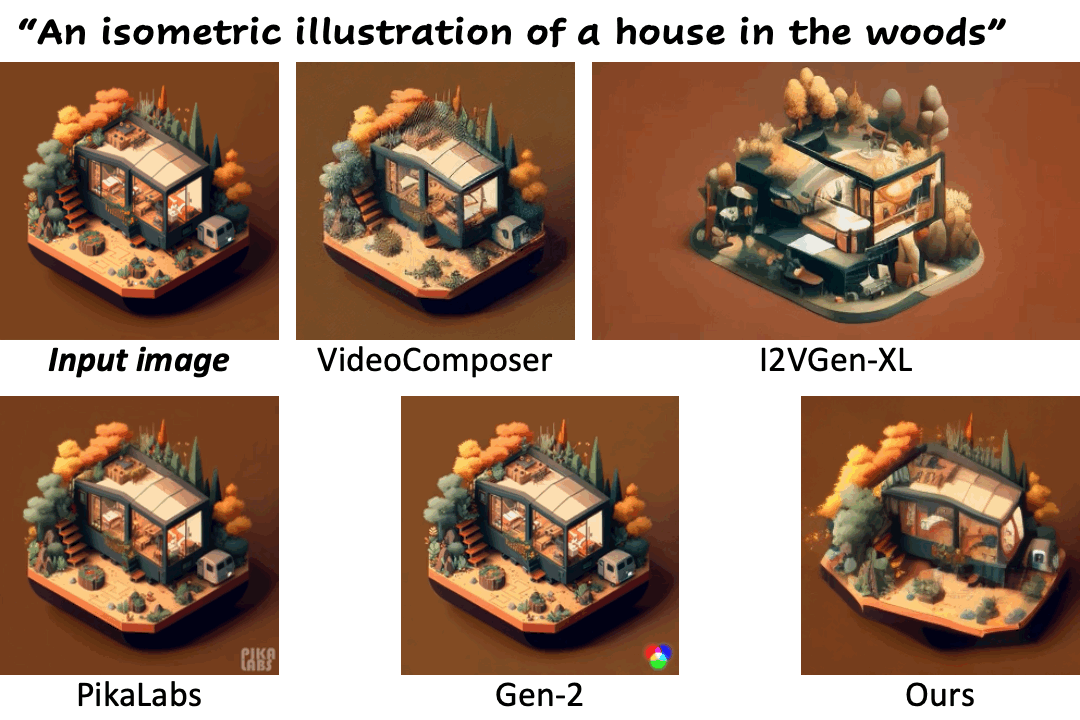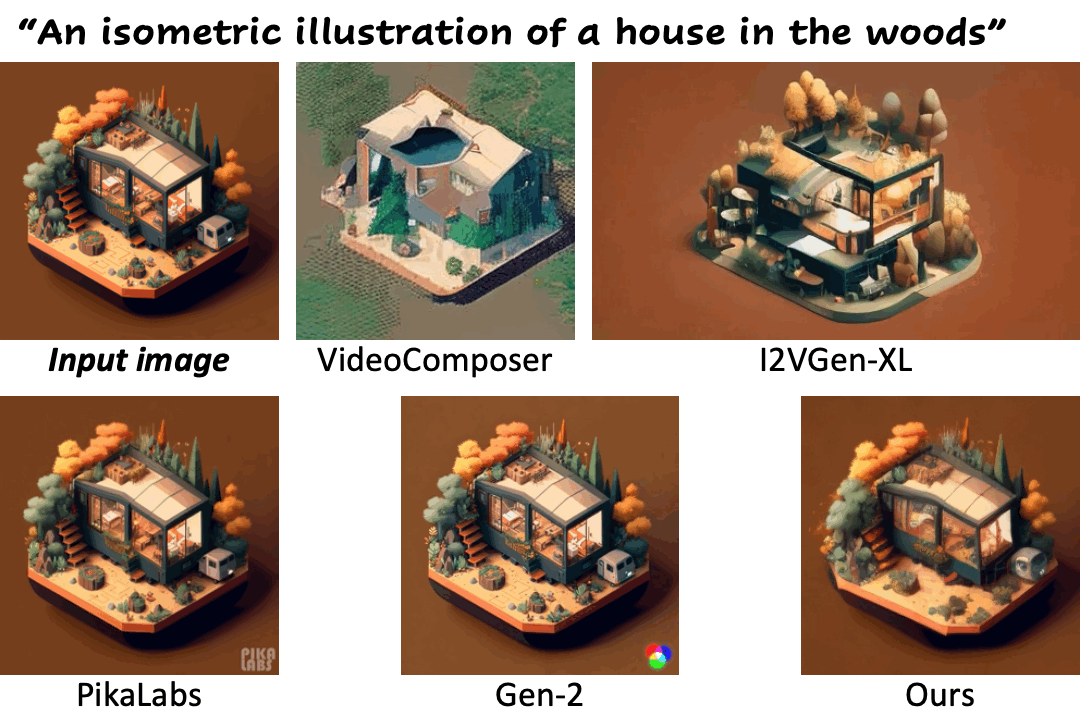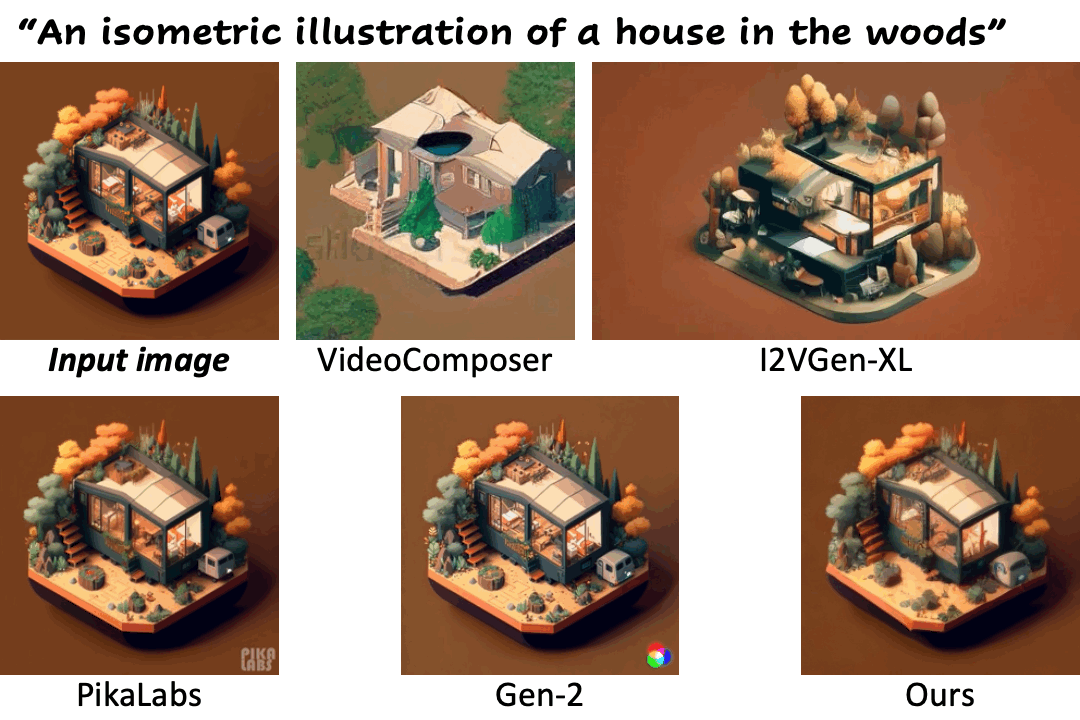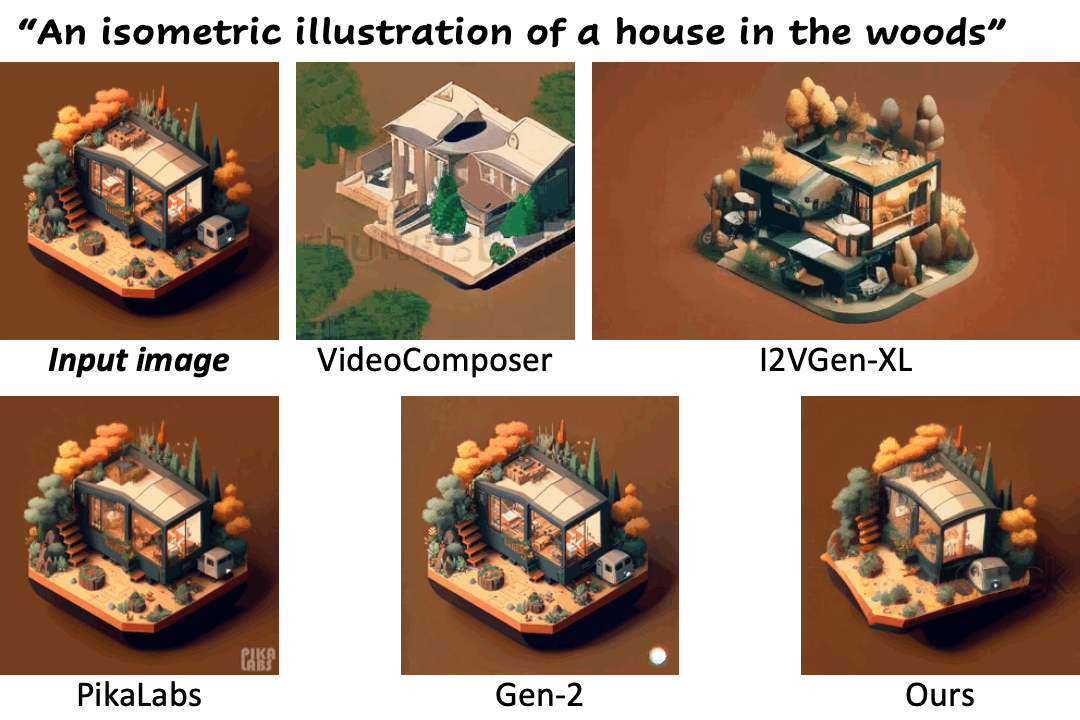

Motion control using text
| "Man talking" | PikaLabs | Gen-2 | DynamiCrafter (Ours) | DynamiCrafterDCP (Ours) |
|---|---|---|---|---|
 |
||||
| "Man waving hands" | ||||
|
||||
| "Man clapping" | ||||
|
||||
| "Girl dancing" | PikaLabs | Gen-2 | DynamiCrafter (Ours) | DynamiCrafterDCP (Ours) |
|---|---|---|---|---|
 |
||||
| "Girl waving hands" | ||||
|
||||
| "Girl twirling her hair" | ||||
|
||||
Applications
Storytelling with shots. We can use ChatGPT (enpowered by DALL·E 3) to create several shots of a story and then generate storytelling videos by animating these shots. [Image source]
| "A disheartened bear sat by the lake, hanging its head." | "He is meeting a girl and introducing himself." | ||||||
|---|---|---|---|---|---|---|---|
 |
 |
||||||
 |
"He chatted happily with that girl by the lake." | "Before leaving, the girl told him to be positive." |  |
||||
 |
 |
||||||
Generative frame interpolation (@320×512 resolution).
| Input starting frame | Input ending frame | Generated video |
|---|---|---|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
Looping video generation (@320×512 resolution).
Other controls
FPS control.
| "An anime scene with windmills standing tall in a field and blue sky" | FPS = 30 | FPS = 10 | FPS = 5 |
|---|---|---|---|
 |
 |
 |
 |
| "A boat moving on the sea" | FPS = 30 | FPS = 10 | FPS = 5 |
 |
 |
 |
 |
Multi-cond classifier free guidance. Higher stxt and simg indicates a more significant impact for the text prompt and image condition, respectively.
| "A statue of two men with wings are dancing" | stxt=simg=7.5 | stxt=1.2, simg=7.5 | stxt=7.5, simg=1.2 |
|---|---|---|---|
 |
 |
 |
 |
Ablation study
Dual-stream image injection.
| "A camel in a zoo enclosure" | Ours | w/o ctx | w/o VDG | w/o λ | OursG |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
Training paradigm. Visual comparisons of the context conditioning stream learned in one-stage and our two-stage adaption strategy.
| "A man hiking in the mountains with a backpack" | One-stage | Our adaption |
|---|---|---|
 |
 |
 |
Training paradigm.
| "A girl with short blue and pink hair speaking" | Ours | Fine-tuning entire. | 1st frame condtion |
|---|---|---|---|
 |
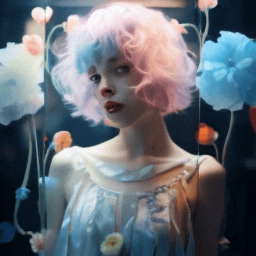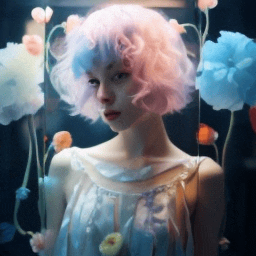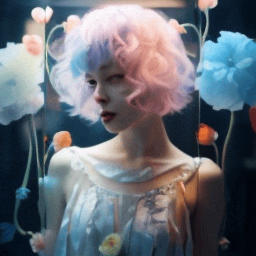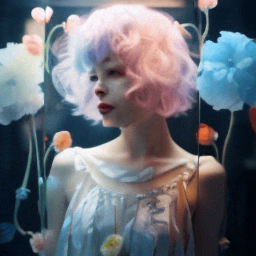 |
 |
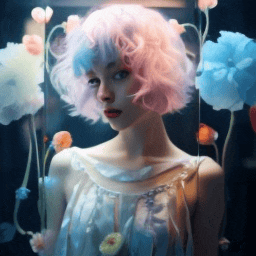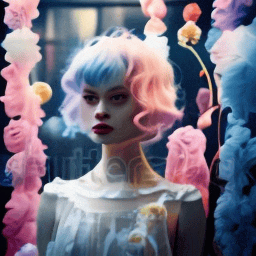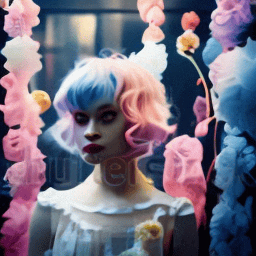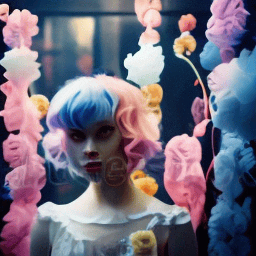 |
Limitations
Challenging case in terms of image content understanding.
| "Moving clouds in an anime scene" | Output |
|---|---|
 |
 |
Inability to generate specific motions since the dataset lacks precise motion descriptions.
| "Girl rubbing her eyes" | Output |
|---|---|
 |
 |
Inheriting slight flickering artifacts and human face distortion issue from the pre-trained low-resolution T2V model.
| "Old man walking with his wife" | Output |
|---|---|
 |
 |