Mature man standing on a train. he is typing on his smart phone
Pyro sparklers ice fire celebration fireworks
Fire spot at stove for cooking thai style
Woman with a yellow raincoat walking on a black sand beach in hvitserkur, vatnsnesvegur located in iceland
Young bald eagle feeding on carrion skeleton
Gorgeous hispanic woman undoing ponytail shaking long hair slow motion
Fast water - colorado river
A wide shot of a beach and cliff with the ocean. camera moves backward
Slow motion avocado with a stone falls and breaks into 2 parts with splashes
4k a food plate composition at the wood countryside table in oak grove watching her smartphone drinking coffe and going to eat her gastronomic breakfast with grilled bread toasts with blue creamy
Wind turbine from aerial view - sustainable development, environment friendly. wind mills during bright summer day
Typing on a laptop keyboard. lateral dolly. 2 videos in 1. woman working on a laptop
A gray domestic cat looks into the distance. close-up portrait. pets
Mixture of legumes in a wooden bowl
Close up of unrecognisable clown smiling large to the camera in slow motion
Baking cookies in bakery oven with high temperature. shot in 4k resolution
Moscow / russia - april 26 2018: trio singing a religious hymn inside russian church, beautiful voices and acoustics, camera swipes across and up revealing detailed wall decorations
Sunset cloud in blue evening skies, sun rays with beautiful cloud time lapse. aerial pan shot over clouds during beautiful sunset time-lapse, beautiful timelapsed sunrise through the many layers. fhd
A couple takes their own picture with a cell phone
Vertical shot natural aggressive volcanic landscape - hot spring water stream surrounded by fumaroles. geothermal field on active volcano: travel destinations to observe volcanoes activity
Nice doctor pediatrician stands against background of pediatric department with working doctors. young smiling girl pediatrician looks into camera
Aerial ireland-flight along galway coast 2006
Beautiful happy girl riding in speed boat freedom on destination travel adventure vacation
Longer Video Inference (32 frames)
Brushing barbecue sauce on ribs, closeup, slow motion
Burning grass of the field in thailand
Boy reading book
Whole coconut isolated on black background
Slow motion, close-up of splashing fountain of water
Professional male potter working with clay on potter's wheel in workshop, studio. handmade, art and handicraft concept
Circa 1919 - a navy officer at a desk signs documents 1919
Seagulls and geese
Scientists or chemists working in a laboratory together. 4k resolution
Fountain stone flower in moscow exhibition center, slow motion
Aerial panoramic view of inland of ua pou island, lush green hill slopes and clouds over mountains - south pacific ocean, marquesas islands, landscape panorama of french polynesia
3d rendered orange juice splash after the dropping high speed shooting simulation with macro focus effect
Side view of healthy and tropical papaya salad with peanuts, at resturant , thailand
Birds on the rock at the waterfall
A physician advising a senior male patient about pills
Animation of rotation dna helix or molecule from glass and crystal. animation of seamless loop
Sandy rocky canyon of antelope
Timelapse of stars above the landscape of maui in hawaii from the summit of haleakala
Abstract
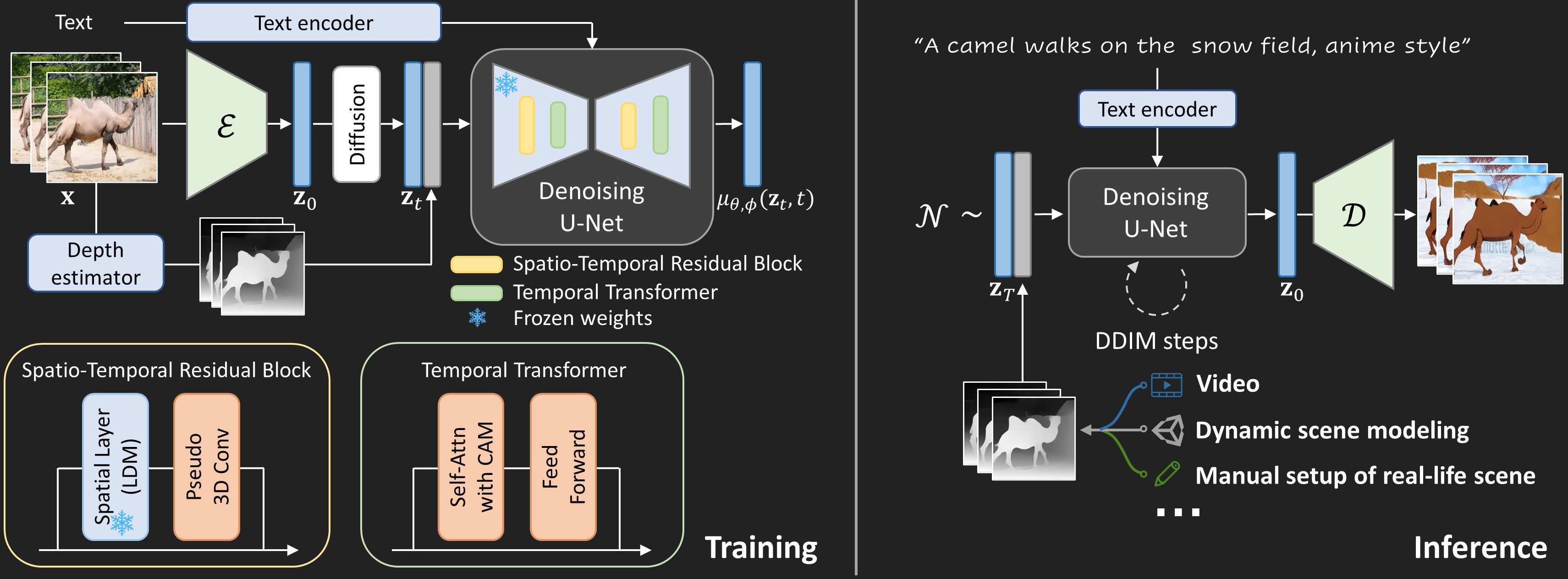
Creating a vivid video from the event or scenario in our imagination is a truly fascinating experience. Recent advancements in text-to-video synthesis have unveiled the potential to achieve this with prompts only. While text is convenient in conveying the overall scene context, it may be insufficient to control precisely. In this paper, we explore customized video generation by utilizing text as context description and motion structure (e.g. frame-wise depth) as concrete guidance.
Our method, dubbed Make-Your-Video, involves joint-conditional video generation using a Latent Diffusion Model that is pre-trained for still image synthesis and then promoted for video generation with the introduction of temporal modules. This two-stage learning scheme not only reduces the computing resources required, but also improves the performance by transferring the rich concepts available in image datasets solely into video generation. Moreover, we use a simple yet effective causal attention mask strategy to enable longer video synthesis, which mitigates the potential quality degradation effectively.
Experimental results show the superiority of our method over existing baselines, particularly in terms of temporal coherence and fidelity to users' guidance. In addition, our model enables several intriguing applications that demonstrate potential for practical usage.
Method Overview
Application
Real-life scene to video
Real-life scene
Text2Video-zero+CtrlNet
LVDMExt+Adapter
Ours
"A dam discharging water"
"A futuristic rocket ship on a launchpad, with sleek design, glowing lights"
3D scene modeling to video
3D scene modeling
Text2Video-zero+CtrlNet
LVDMExt+Adapter
Ours
"A train on the rail, 2D cartoon style"
"A Van Gogh style painting on drawing board in park, some books on the picnic blanket, photorealistic"
"A Chinese ink wash landscape painting"
Video re-rendering
Original video
SD-Depth
Text2Video-zero+CtrlNet
LVDMExt+Adapter
Tune-A-Video
Ours
"A tiger walks in the forest, photorealistic"
"An origami boat moving on the sea"
"A filled chocolate moving on the road"
"A camel walking on the snow field, Miyazaki Hayao anime style"
"A waterfall in the middle of a glacier"
"An astronaut is walking on the moon, cartoon style"
Video re-rendering (with concurrent works)
Original video
SD-Depth
ControlVideo
VideoComposer
Gen-1
Ours
"A camel walking on the snow field, Miyazaki Hayao anime style"
"A toy cat sitting on the ground at Times Square, photorealistic"
"A black-and-white robot cow walking in a river"
"A waterfall in the middle of a glacier"
Citation
@article{xing2023make,
author = {Xing, Jinbo and Xia, Menghan and Liu, Yuxin and Zhang, Yuechen and Zhang, Yong and He, Yingqing and Liu, Hanyuan and Chen, Haoxin and Cun, Xiaodong and Wang, Xintao and Shan, Ying and Wong, Tien-Tsin},
title = {Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance},
journal = {arXiv preprint arXiv:2306.00943},
year = {2023}
}
This page is modified based on the LVDM project page.