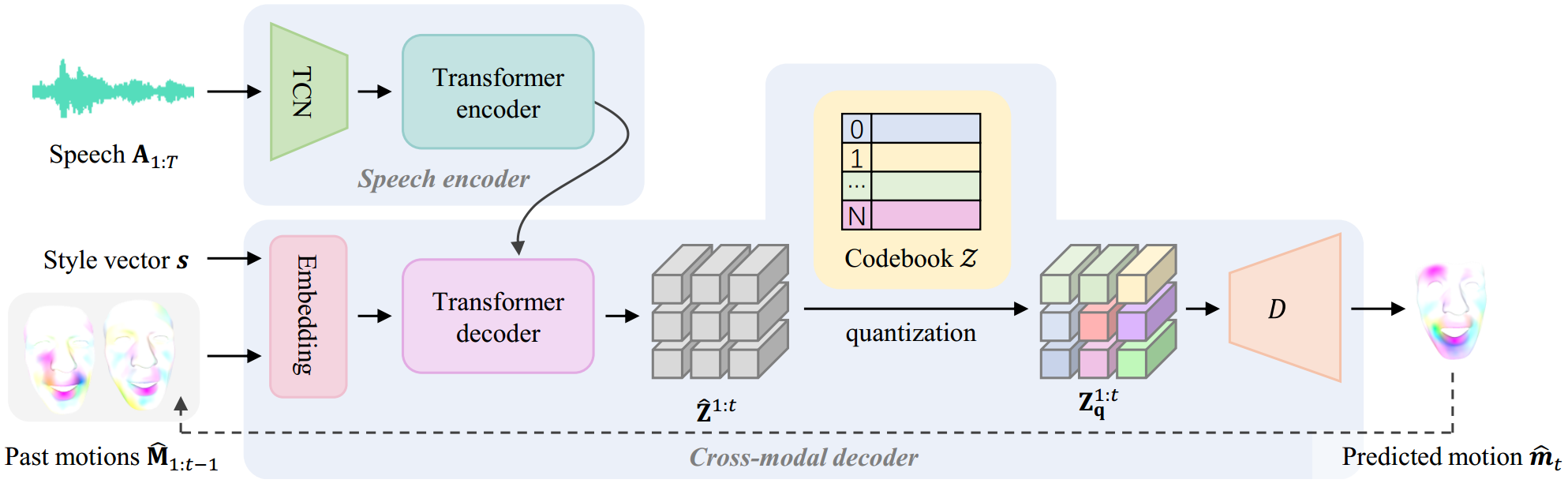
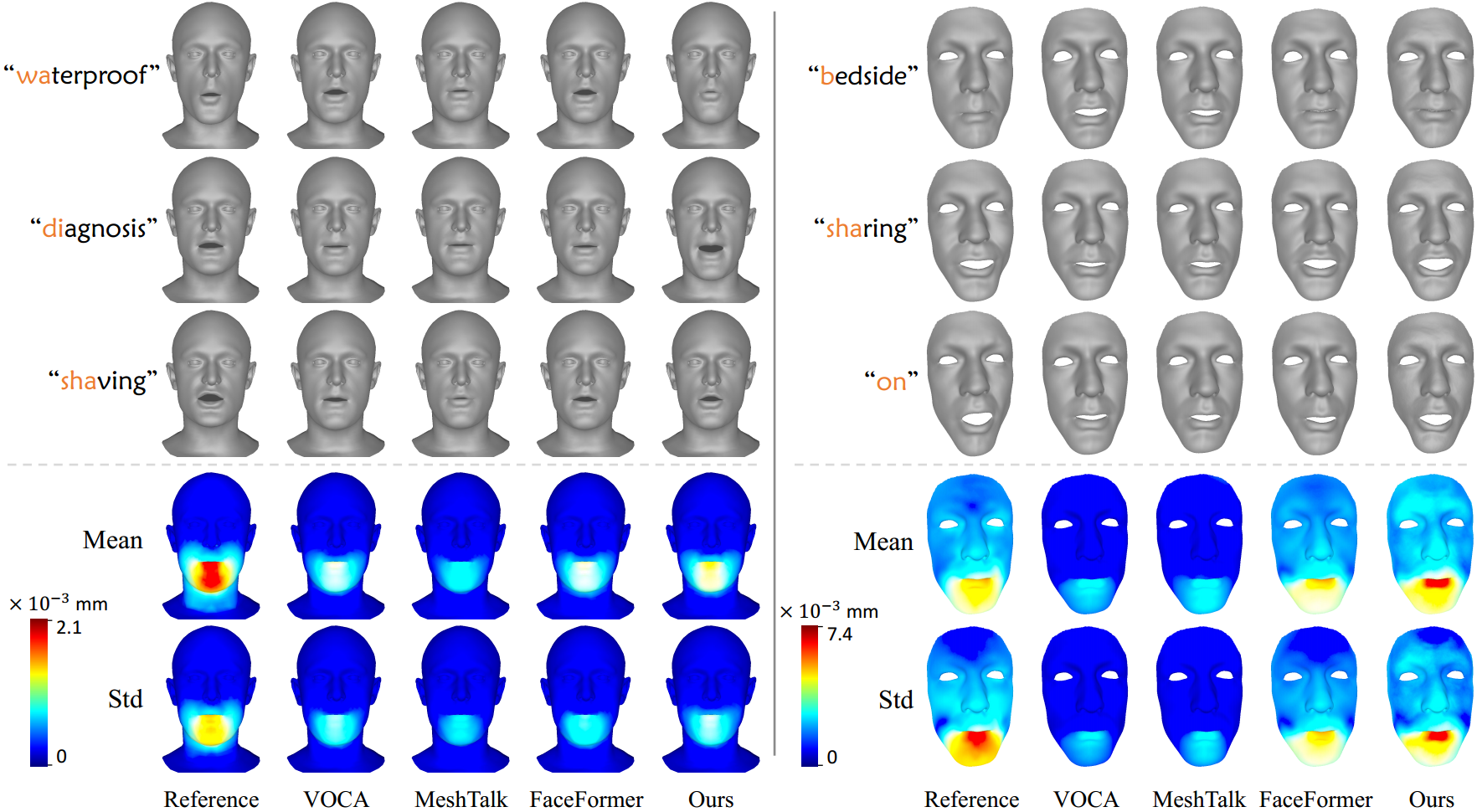
Method
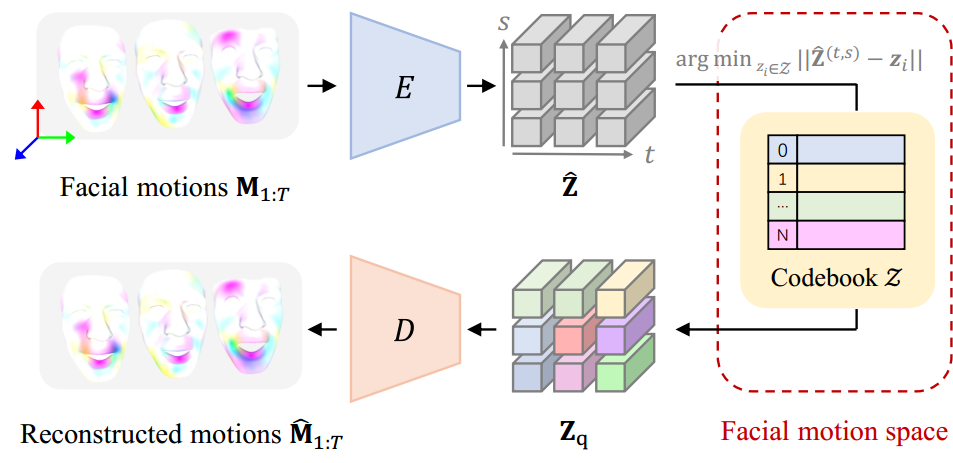
Discrete Motion Prior Learning
CodeTalker first learns a discrete context-rich facial motion codebook by self-reconstruction learning over real facial motions.
Speech-Driven Motion Synthesis
It then autoregressively synthesize facial motions through code query conditioned on both the speech signals and past motions.